サクラエディタのIPv6正規表現
([0-9a-fA-F]{1,4}:){7}[0-9a-fA-F]{1,4}
KLab Expert Camp 5 - Day1の進め方
KLab Expert Camp 5 - Day1の進め方
PowerPointスライドを見ればわかるのかな…と思ったのですが、少しコツがいるので
書いておきます。
「このステップのコードの雛形」にあるgit showを実施する。
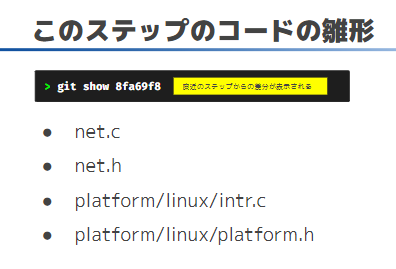
そうすると、一つ前のstepで使ったファイル(下図だとdummy.c)で
今回のstep用に追加された行がプラス(+)で表示されます。
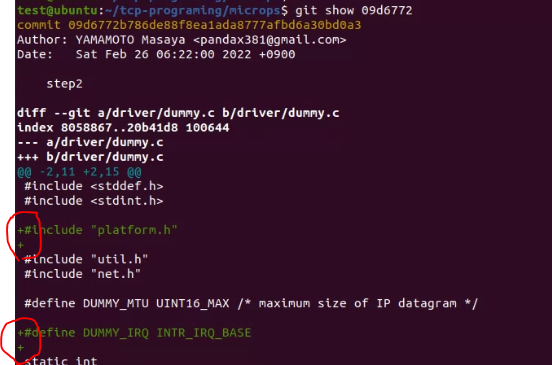
今回のstepで新たに作成されたファイルの場合は、全部の行がプラス(+)で表示されます。(下図だとintr.c)
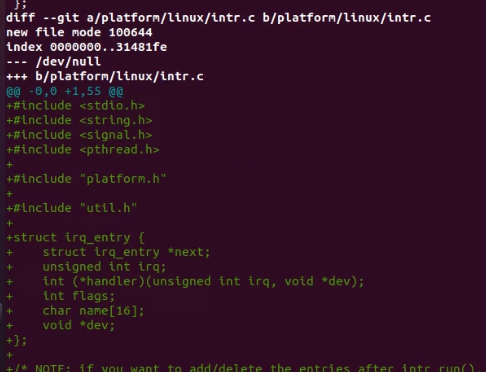
既存のファイル(dummy.c)は、差分を追記
新規のファイル(intr.c)の場合は、作成
をします。
PowerPointスライドは何が書いてあるか…というと回答です。
新規のファイル(intr.c)

下図のミドリ色の字が回答です。
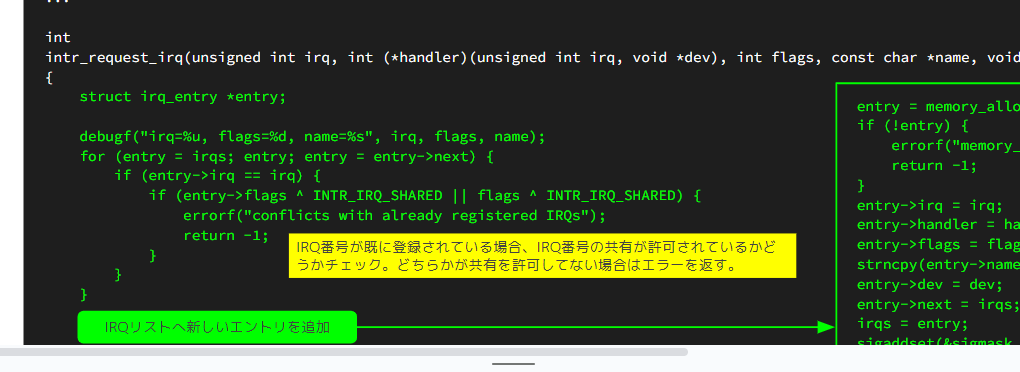
ミドリ色の回答全部張り付ければ、動きます。
KLab Expert Camp 5 - Day1やってみた
初っ端でつまずきました。。
「step1 デバイス管理」のところ

test@ubuntu:~/tcp-programing/microps$ ./test/step1.exe
20:34:03.613 [I] net_init: initialized (net.c:151)
Segmentation fault
test@ubuntu:~/tcp-programing/microps$
セグメンテーションフォルトでちゃって直せない。core dumpはくように設定した。
test@ubuntu:~/tcp-programing/microps/test$ ./step1.exe
20:41:36.392 [I] net_init: initialized (net.c:151)
Segmentation fault (core dumped)
test@ubuntu:~/tcp-programing/microps/test$
test@ubuntu:~/tcp-programing/microps/test$ ls
core step0.c step0.o step1.exe test.h
net.h.save step0.exe step1.c step1.o
dumpの中身は以下
test@ubuntu:~/tcp-programing/microps/test$ gdb step1.exe core
GNU gdb (Ubuntu 9.2-0ubuntu1~20.04) 9.2
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from step1.exe...
[New LWP 2164]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Core was generated by `./step1.exe'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x000055a6d1967687 in dummy_init () at driver/dummy.c:33
33 dev->type = NET_DEVICE_TYPE_DUMMY;
dev->type = NET_DEVICE_TYPE_DUMMY
ここでエラーになったっぽい。「driver/dummy.c」に設定されてた。

net.hで定義?してるっぽいので確認。ちゃんと書いてある。。

よくわからず、、make cleanしてみました。そしたらちゃんと動いた!
test@ubuntu:~/tcp-programing/microps/test$ ./step1.exe
21:13:04.018 [I] net_init: initialized (net.c:151)
21:13:04.018 [I] net_device_register: registered, dev=net0, type=0x0000 (net.c:39)
21:13:04.018 [D] dummy_init: initialized, dev=net0 (driver/dummy.c:42)
21:13:04.018 [D] net_run: open all devices... (net.c:128)
21:13:04.018 [I] net_device_open: dev=net0, state=up (net.c:59)
21:13:04.018 [D] net_run: running... (net.c:132)
21:13:04.018 [E] net_device_output: already opened, dev=net0 (net.c:88)
21:13:04.018 [E] main: net_device_output() failure (test/step1.c:43)
21:13:04.018 [D] net_shutdown: close all devices... (net.c:141)
21:13:04.018 [E] net_device_close: already opened, dev=net0 (net.c:69)
21:13:04.018 [D] net_shutdown: shutting down (net.c:145)
test@ubuntu:~/tcp-programing/microps/test$
switchdev続き
ninjaインストール続き。以下ではダメだった。
git clone git://github.com/ninja-build/ninja.git && cd ninja
./configure.py --bootstrap
cp ninja /usr/bin/
普通に
apt install ninja-build
インストールできた。![]()
もう一回コンパイル実施。ccがない模様。
gccとか入ってないかもしれない。
aa@aaa-VirtualBox:~/qemu$ ./configure --target-list=x86_64-softmmu --extra-cflags=-DDEBUG_ROCKER
Using './build' as the directory for build outputERROR: "cc" either does not exist or does not work
そもそもqemuに必要なパッケージがどれかよくわかってないのに
やみくもにやっている状態になってしまっている。
以下のURLにて説明あった。apt build-depというのを実施する必要あり。
QEMU で Raspberry Pi 3 用のバイナリを動かす - Qiita
apt build-dep <パッケージ名> で <パッケージ名> に該当するもののビルドに必要なパッケージをまとめてインストールできるようです
- sudo vi /etc/apt/sources.list
- :%s/# deb-src/deb-src/
- :wq
- apt updateを実行してから再度 apt build-depを実行
- sudo apt build-dep qemu
上記URLの手順の1~5実施したら
一応、コンパイルとおる感じになった。

switchdevというデバイスドライバ

UARTのピンアサイン確認方法
◽️
The IoT Hacker's Handbook: A Practical Guide to Hacking the Internet of Things
Aditya Gupta Walnut, CA, USA
ISBN-13 (pbk): 978-1-4842-4299-5
https://doi.org/10.1007/978-1-4842-4300-8
Copyright © 2019 by Aditya Gupta
ISBN-13 (electronic): 978-1-4842-4300-8
という本だと、起動時に電圧が上がってすぐさがれば、Txピン
———————-
デバイスを再起動し、残りのパッドとGNDの間の電圧を測定します。 起動時の最初の大量のデータ転送により、最初の10〜15秒の間に電圧値の大きな変動に気付くでしょう。 このピンはTxピンになります。
———————-
◽️YouTubeで同じようなことしている動画も確認
UARTを直接測ったときの抵抗値があり(Rgrnが30kΩ)、UART直接ではなくて上流の電源(Vcc)側から測って抵抗がない(Rvccが0Ω)になるのがVcc(電源)らしい。(下のYouTube のキャプチャの表一行目の話をしてます)

UARTで直接測ってるときの様子
赤い線を計測したいピンにつける
黒のグランド用の線はボードのどこかシールドになってるところに接続

上流の電源(Vcc)側から測ってるときの様子
赤い線をVcc、黒い線を計測したいピンにつける

YouTube の人は、電源(Vcc)とグランド(grn)をまず見つけるっていうのをやってるみたい。そのあと、Tx/Rxを見つける作業する。確かにまず電源見つけないと危ないからかな。
Vcc見つかった

ネットワークスペシャリスト試験過去問
このブログは、Advent Calendar 2019 大國魂(ITブログ)の17日目です。
ネットワークスペシャリストの試験を5年ぐらい受験しているのですが、なかなか受かりませんが、過去問を結構勉強して知見がたまってきたので、公開したいと思います。
平成29年 午後1 問3 設問3(4)
めちゃくちゃピンポイントですが、この問題を取り上げてみます。以下(4)の問題分だけ引用してみます。
本文中の下線⑤について、経路のループを防止するために必要な経路制御を40字以内で述べよ。
下線⑤前後の文章は以下
I主任:そうですね。そういえば一点注意が必要です。経路情報の再配布を行うときは、経路のループを防止しなければいけません
Oさん:わかりました。⑤経路のループを防止する経路制御を行います。
再配布されるときの状態としては以下画像のような感じです。
R2とR3が同じASで、R4とR5が同じASです。下図だとちょっとわかりずらいので、念のため。

③と⑥が再配布している場所です。⑥の再配布をしてしまうことで
問題がおきてしまうというのがIPAの回答でした。
IPAの回答
eBGPからOSPFへ再配布された経路を再びeBGPへ再配布しない
というものです。
ループが実際におきるところは
R7のところです。
R7がR8から受け取ったサーバの経路情報(7.7.7.7)とR5から再配布で戻ってきたサーバの経路情報(7.7.7.7)を比べて、R5のほうが勝ってしまいます。

特に深く考えないでいるとR8からきたルートのほうが強いんじゃないかと思ってしまいますが、OSPF→BGPに再配布された入ってきたルート(最初の図の⑥)のメトリックが、R8からきたルートのメトリックより高いことがあるというのがポイントだと思います。(たぶん高くなると思います。すいません、たぶんで。R5のルートのほうがメトリック高くないとループがおきない→つまり、問題の条件が起きえない。)
R5とR8で動いているのがどんなIGP(ripv2、EIGRP、OSPF)でも起こりえるようなループなのではないかと思われます。
そのため、下図のようなループがおきます。

⑫以降は、R1、R2、R4、R7、R5、R3のルータでループし続けます。(TTLがなくなるまで)
IPAの回答を実際の機器設定まで落とし込めるか?
OSPFからBGPに再配布してきたルートのメトリック設定する方法をちゃんと探してみました。上のほうで、たぶんと言ってしまいましたが、以下設定とかがありそうな設定かと思います。
シナリオ 2
(network コマンドか redistribute コマンドのいずれかによって)BGP に挿入されたルートが IGP(RIP または EIGRP、もしくは OSPF)を使用している場合、MED のメトリック値は IGP のメトリックから受け継ぎ、ルートはこの MED を使用して eBGP ネイバーにアドバタイズされます。
このシナリオでは、次のネットワーク構成を使用しています。
~途中のconfigとか省略~
R2 では RIP と BGP の両方が実行されています。 show ip bgp コマンドを実行すると、プレフィックス 10.0.0.0 ネットワークのメトリックは 1 になっていることに気付きます。この値は、RIP から受け継いだものです。
R2 の出力結果は、次のとおりです。
しかし、eBGP を実行中の R3 には、IGP から受け継いだ MED 値に基づいてネットワークがアドバタイズされています。 この例では RIP です。 プレフィックス 10.0.0.0 には、RIP のメトリック値 1 の IGP MED 値がアドバタイズされます。
これは、次の出力結果で確認できます。



https://www.cisco.com/c/ja_jp/support/docs/ip/border-gateway-protocol-bgp/112965-bgpmed-attr-00.html
ここで、再度IPAの回答を確認してみます。
eBGPからOSPFへ再配布された経路を再びeBGPへ再配布しない
別解としては、シスコのサイトの方法を応用した「OSPFからeBGPへ再配布するときメトリックをもとルートよりも大きい値にする。」とかでもよいきがします。
あと、ルートにタグをつけてタグ付いているルートは再配布で戻さないとかがシスコのルータの技とかでありますが、それだとシスコonlyっぽくなってしまうので、ちょっと違う感じがします。
タグつける方法
https://www.infraexpert.com/study/routecontrol16.html
回答の「再び…再配布しない」に含まれるといえば含まれるので、タグつける方法がIPAの回答のもとになった設定かもしれないです。
あとAWSと接続するときの実際のciscoのconfigは、networkコマンドで渡していて、再配布ではないですが、network コマンドか redistribute コマンドのいずれかによってBGP に挿入されたルートのメトリックが…とcisco公式サイトに書いてあるので、netwrokコマンドか再配布(redistribute)かは気にしなくてもいいのかもしれないです。(以下の引用参照して下さい。networkコマンドのところ、デフォゲ渡しているが、細かく渡したいルート指定したかったら、network 192.168.・・・とか書けばよい)
router bgp YOUR_BGP_ASN
neighbor 169.254.255.1 remote-as 7224
neighbor 169.254.255.1 activate
address-family ipv4 unicast
neighbor 169.254.255.1 remote-as 7224
neighbor 169.254.255.1 default-originate
neighbor 169.254.255.1 activate
network 0.0.0.0
https://docs.aws.amazon.com/ja_jp/vpc/latest/adminguide/Cisco.html
azureとかのbgp接続もnetworkコマンドで設定しているので、問題作成した人はどのようにこの問題を作ったかが気になります。
set protocol bgp <Edit>65521</Edit>
set enable
set hold-time 30
set neighbor <Edit>192.168.10.142</Edit> remote-as <Edit>65516</Edit>
set neighbor <Edit>192.168.10.142</Edit> enable
set neighbor <Edit>192.168.10.142</Edit> hold-time 30
set neighbor <Edit>192.168.10.142</Edit> ebgp-multihop 2
set ipv4 neighbor <Edit>192.168.10.142</Edit> activate
set ipv4 network <Edit>192.168.127.0/24</Edit> weight 100
https://qiita.com/yotan/items/367be1a8390713306b5e
過去問のBGPの設定がわかりそうな図は下図です。

◇ ◇ ◇
ネットワークスペシャリストの試験でルーティングの問題は、ちょっと珍しい気がするのでとりあげてみました。
この問題は、色々そぎ落としすぎてよくわからない感じになってしまっている気がしますが、、ネットワークスペシャリストの試験のIPsecの問題とかはすごく勉強になるので、勉強してみるのもいいかもしれません。